The vowel section consists of 38 items designed to diagnose problems in 11 different vowel contrasts (see Table 1). The specific vowel contrasts were chosen based on their functional load (Catford, 1987). This term refers to the "number of pairs of words in the lexicon that [each vowel contrast] serves to keep distinct" (p. 88).
Each item is presented in isolation, and the order in which the items are presented is randomized so the same test can be used any number of times with the same learner. Each item consists of a set of minimal pair sentences, as opposed to minimal pair words, syllables or isolated phonemes. Minimal pair sentences were used to create a diagnostic environment comparable to communication environments in the real world. Thus, a clearer and better picture of the learner’s problems is obtainable and more effective communication can result.
In order to diminish the effects of reading ability and vocabulary knowledge on the results of these two sections, each item is presented with illustrations that highlight the difference between the two sentences in the minimal pair set. Similar methods have been used in other perception instruments as presented in the literature review (e.g. Borden, Gerber, & Milsark, 1983).
| Table 1. Vowel Contrasts in the POSE Test |
| Phonemic Contrast |
Minimal Pair Example |
Functional Loada |
Number of Items |
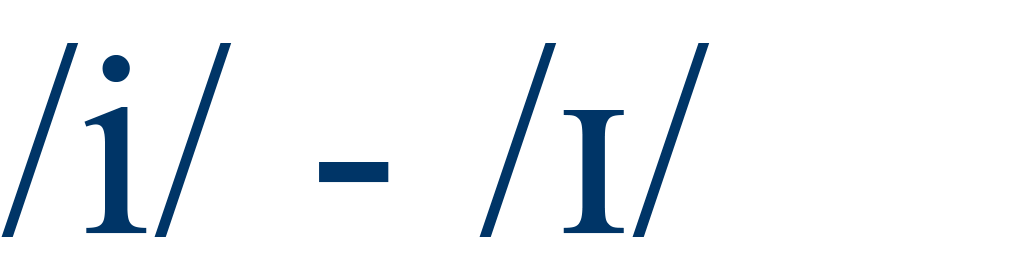 |
beet / bit |
95% |
4 |
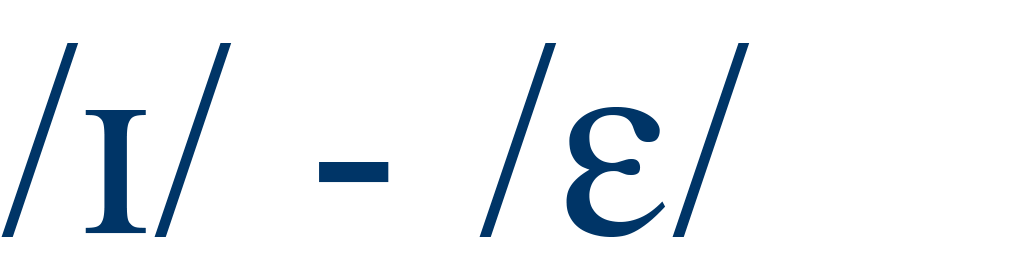 |
bit / bet |
54% |
4 |
 |
bet / bait |
53% |
4 |
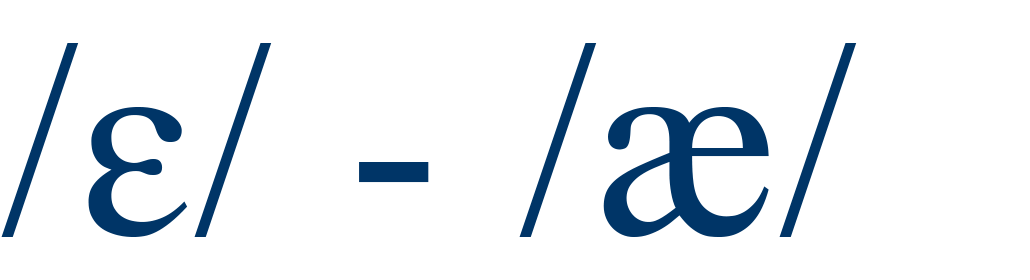 |
bet / bat |
51% |
4 |
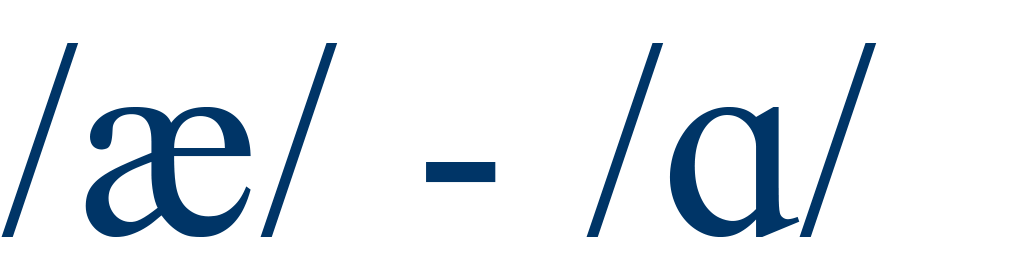 |
cat / cot |
76% |
4 |
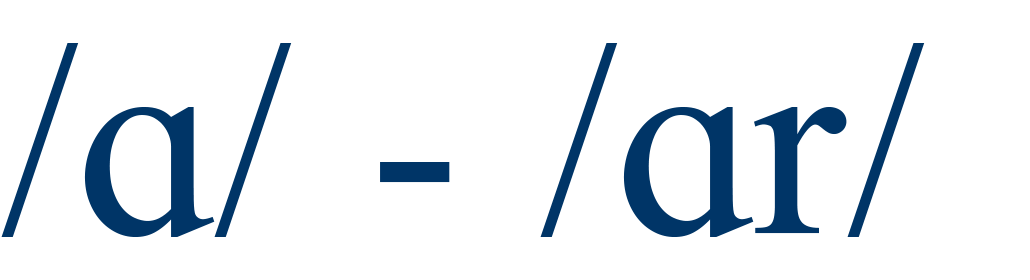 |
cot / cart |
31.5% |
4 |
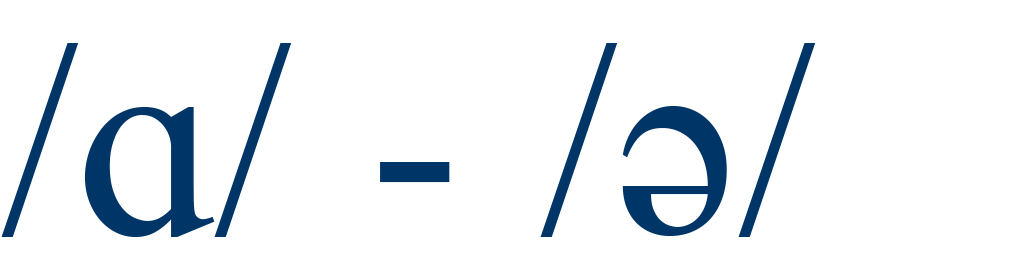 |
cot / cut |
65% |
4 |
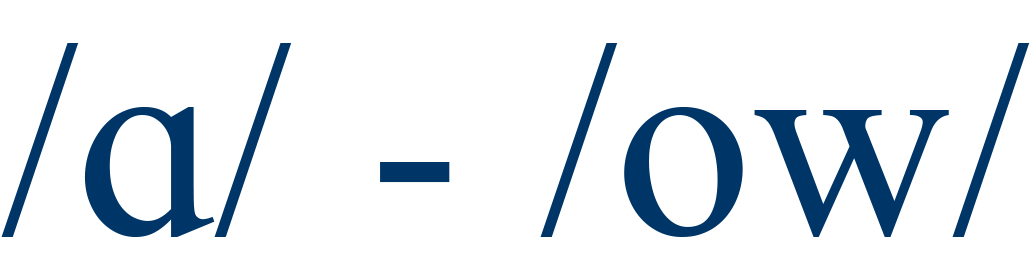 |
cot / coat |
----b |
4 |
 |
cut / curt |
40% |
2 |
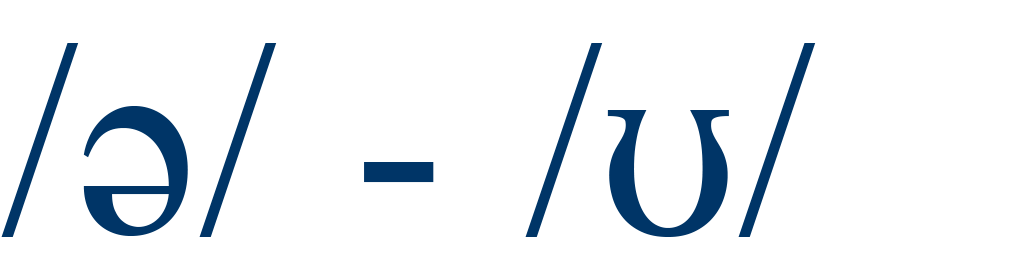 |
putt / put |
9% |
2 |
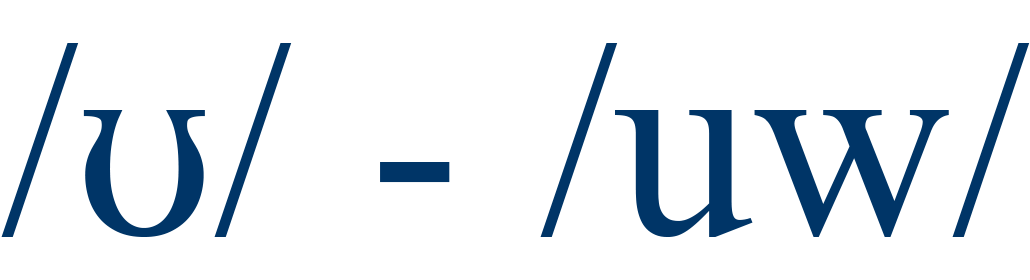 |
pull / pool |
7% |
2 |
| aSource: Catford, 1987, pp. 89-90. bThis contrast was included because of its existence in Pronunciation Matters (Henrichsen, Green, Nishitani & Bagley, 1999) even though no functional load information was available. |
Screenshot of Vowel Section
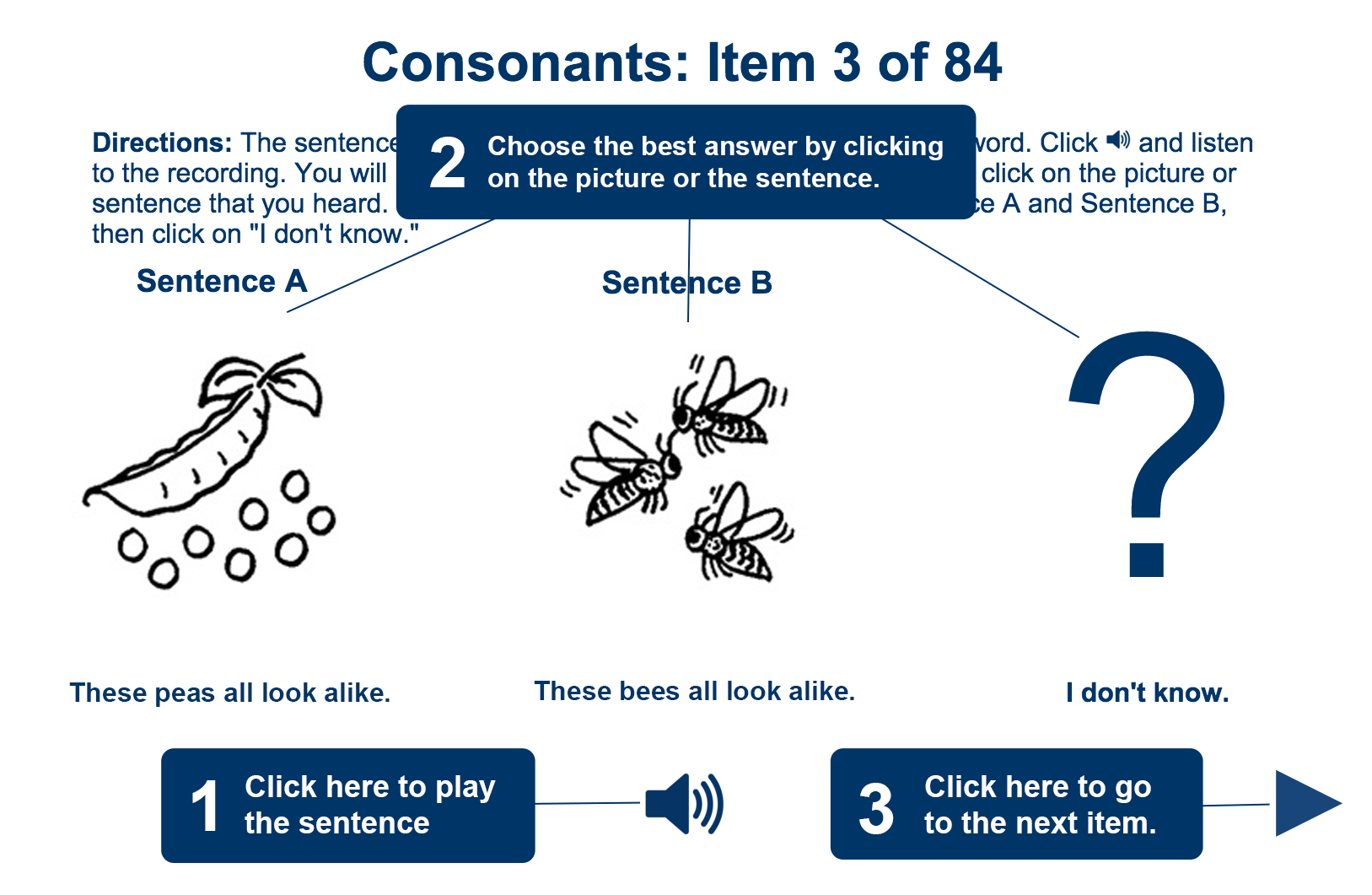
The consonant section consists of 84 items designed to diagnose problems in 25 different consonant contrasts (see Table 1). The specific vowel contrasts were chosen based on their functional load (Catford, 1987). This term refers to the "number of pairs of words in the lexicon that [each consonant contrast] serves to keep distinct" (p. 88).
Each item is presented in isolation, and the order in which the items are presented is randomized so the same test can be used any number of times with the same learner. Each item consists of a set of minimal pair sentences, as opposed to minimal pair words, syllables or isolated phonemes. Minimal pair sentences were used to create a diagnostic environment comparable to communication environments in the real world. Thus, a clearer and better picture of the learner’s problems is obtainable and more effective communication can result.
In order to diminish the effects of reading ability and vocabulary knowledge on the results of these two sections, each item is presented with illustrations that highlight the difference between the two sentences in the minimal pair set. Similar methods have been used in other perception instruments as presented in the literature review (e.g. Borden, Gerber, & Milsark, 1983).
| Table 1. Consonant Contrasts in the POSE Test |
| Phonemic Contrasta |
Minimal Pair Example |
Functional Loadb |
Number of Items |
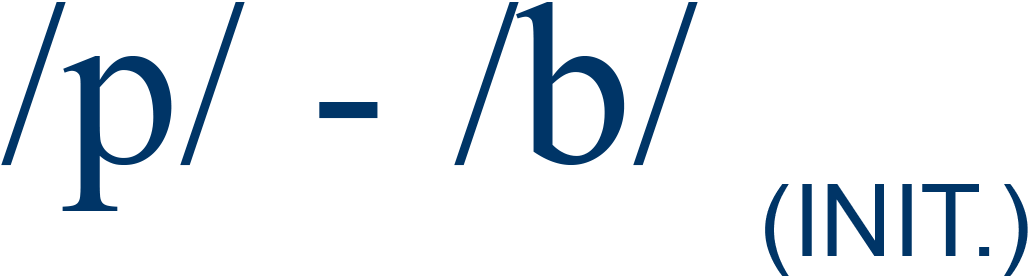 |
pill / bill |
98% |
4 |
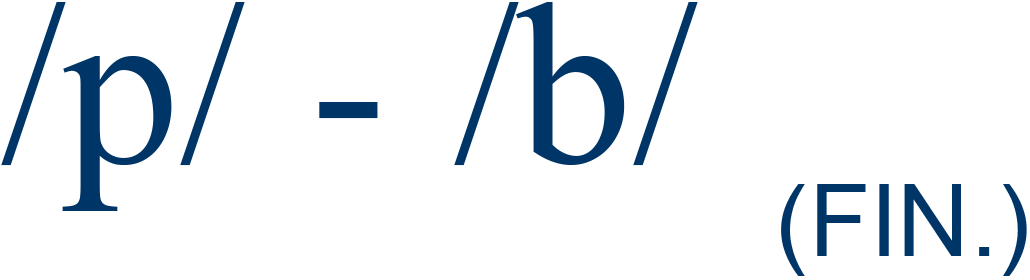 |
cap / cab |
14% |
4 |
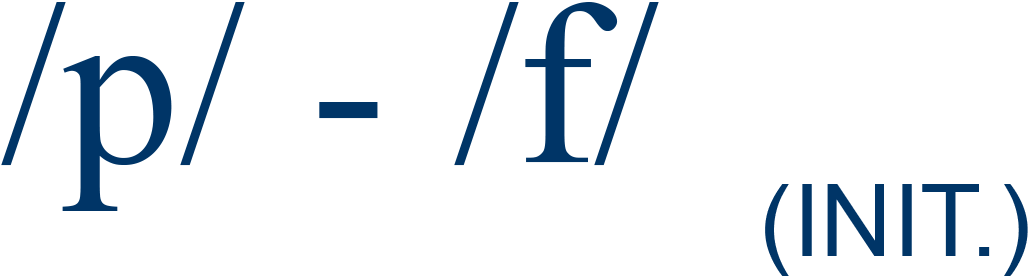 |
pan / fan |
77% |
4 |
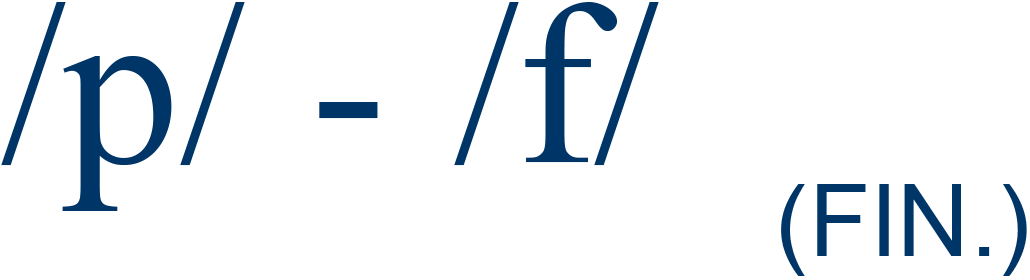 |
cup / cuff |
17% |
4 |
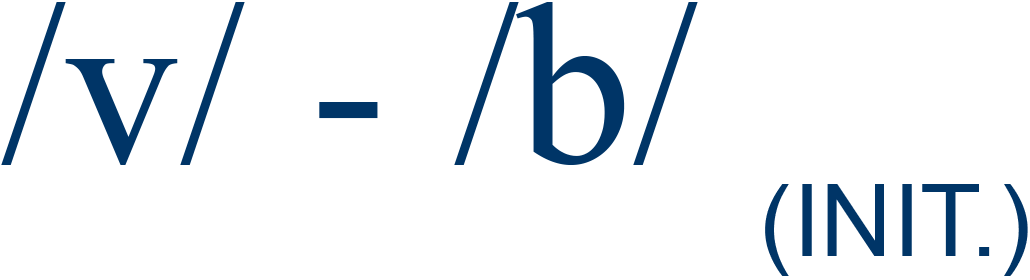 |
vote / boat |
29% |
4 |
 |
vet / wet |
22% |
4 |
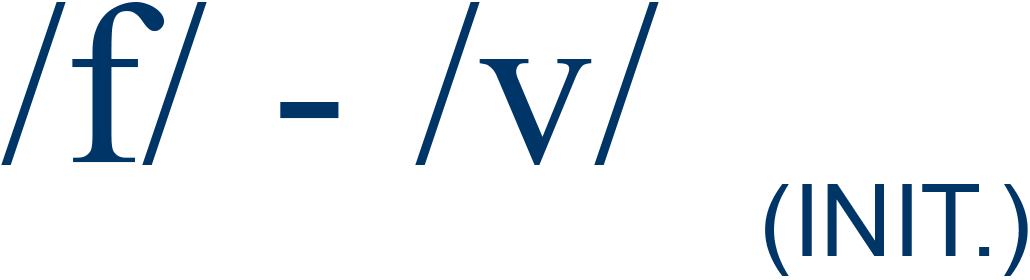 |
fan / van |
23% |
4 |
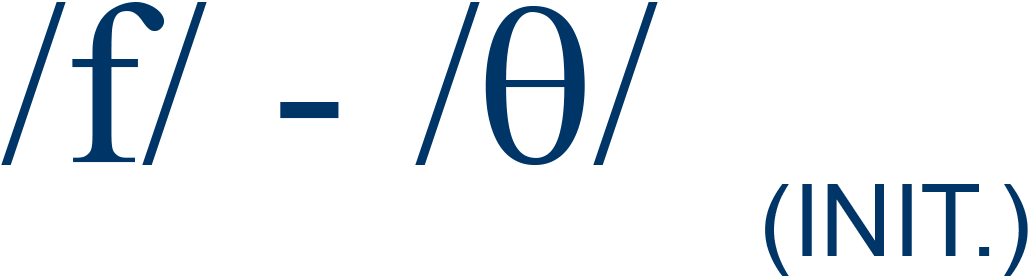 |
free / three |
15% |
4 |
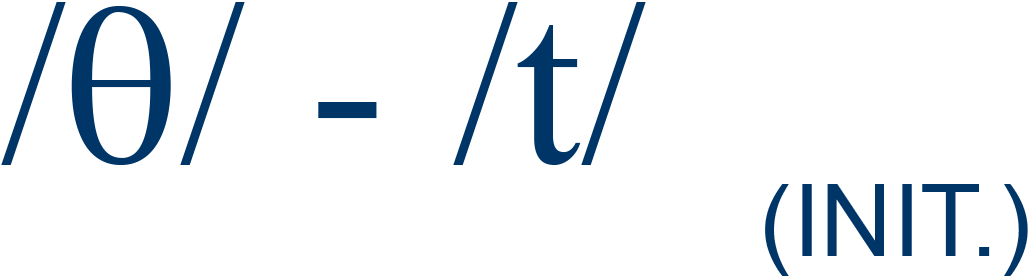 |
thin / tin |
18% |
4 |
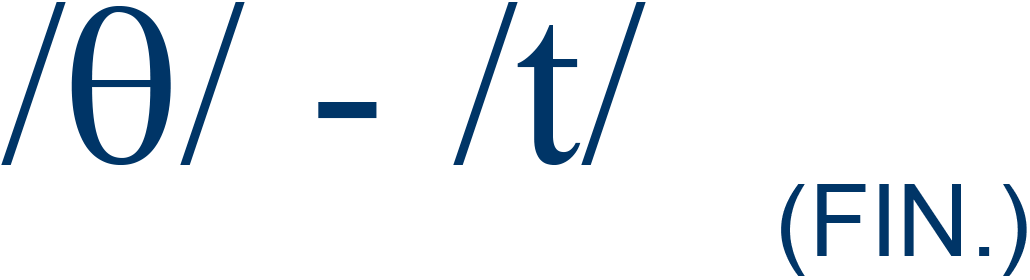 |
bath / bat |
27% |
4 |
 |
think / sink |
21% |
2 |
 |
faith / face |
17% |
2 |
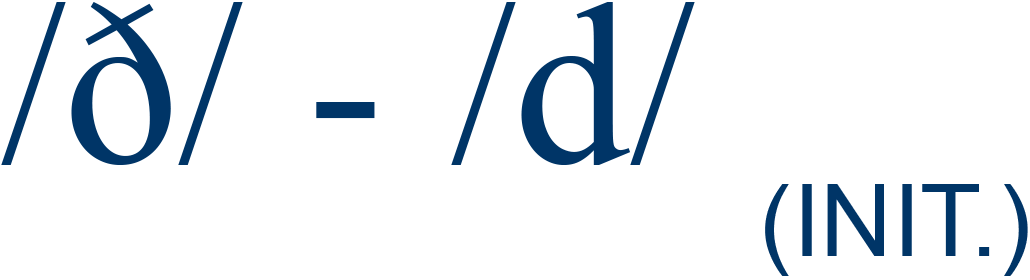 |
they / day |
19% |
2 |
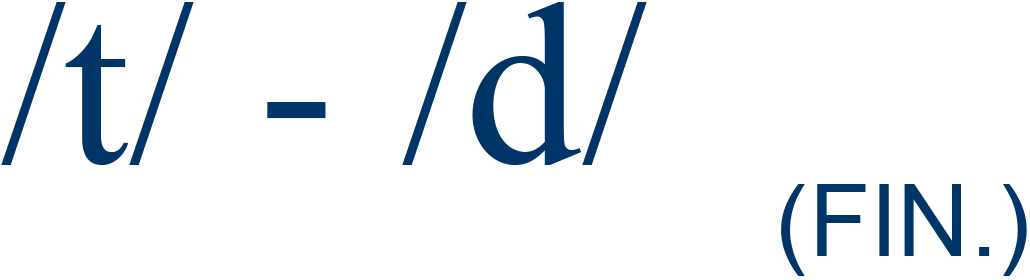 |
cart / card |
72% |
4 |
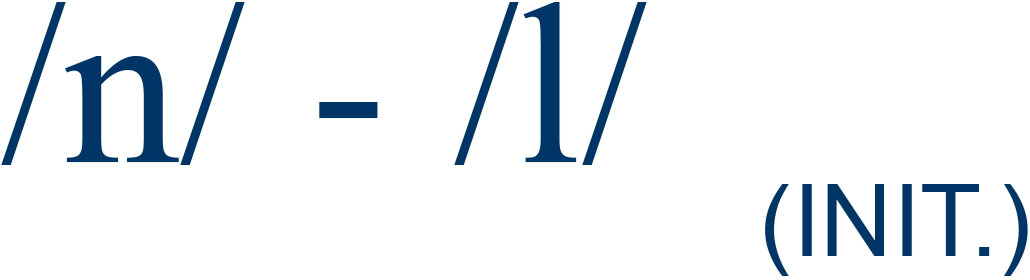 |
nap / lap |
61% |
4 |
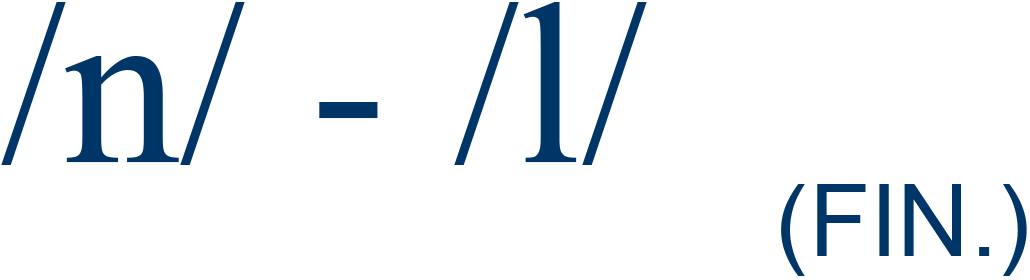 |
bone / bowl |
75% |
4 |
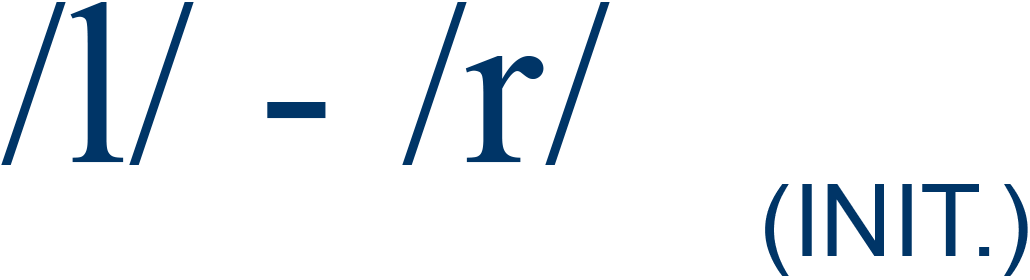 |
lice / rice |
83% |
4 |
 |
ice / eyes |
38% |
4 |
 |
sip / ship |
53% |
2 |
 |
shin / chin |
26% |
2 |
 |
wash / watch |
12% |
2 |
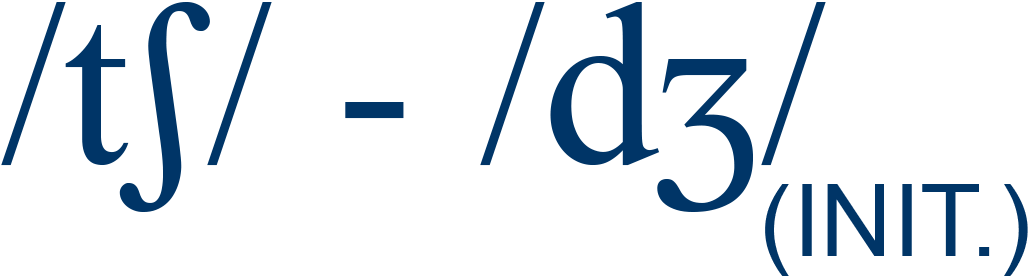 |
choke / joke |
19% |
2 |
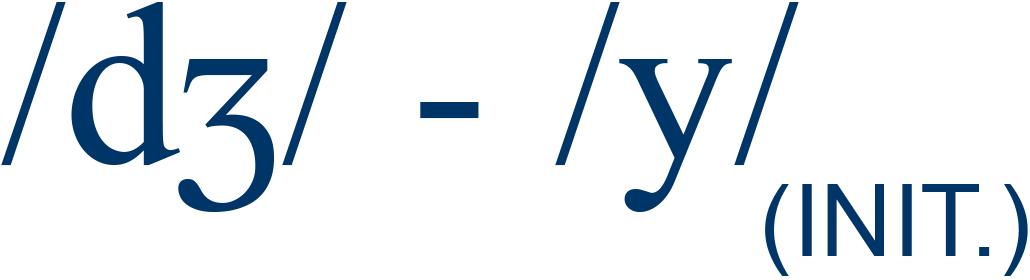 |
jail / Yale |
20.5% |
2 |
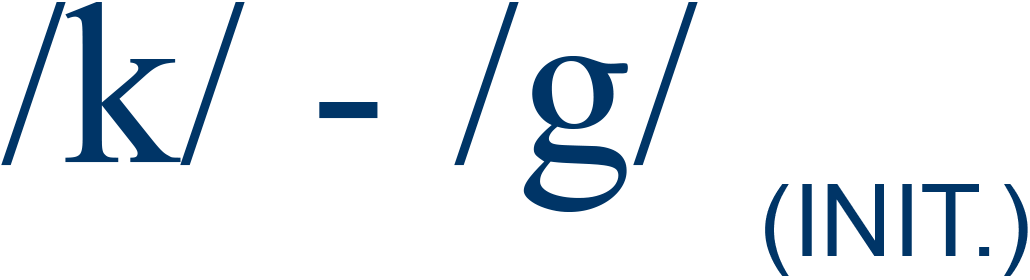 |
coat / goat |
50% |
4 |
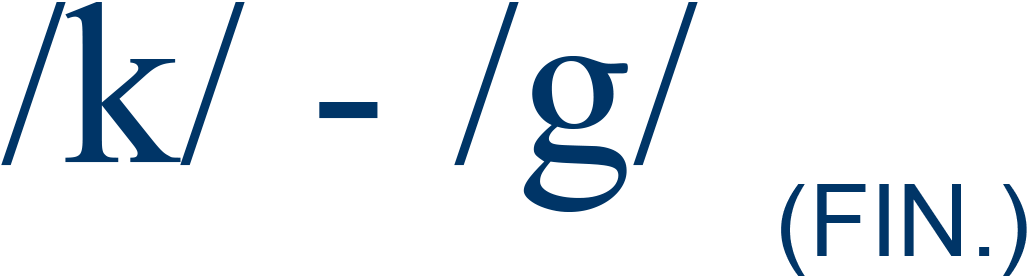 |
tack / tag |
29% |
4 |
| aIncludes both syllable-initial ("INIT.") and syllable-final ("FIN.") sounds. Syllable-medial sounds were not incorporated because no functional load information was available. bSource: Catford, 1987, pp. 89-90. |
Screenshot of Consonant Section
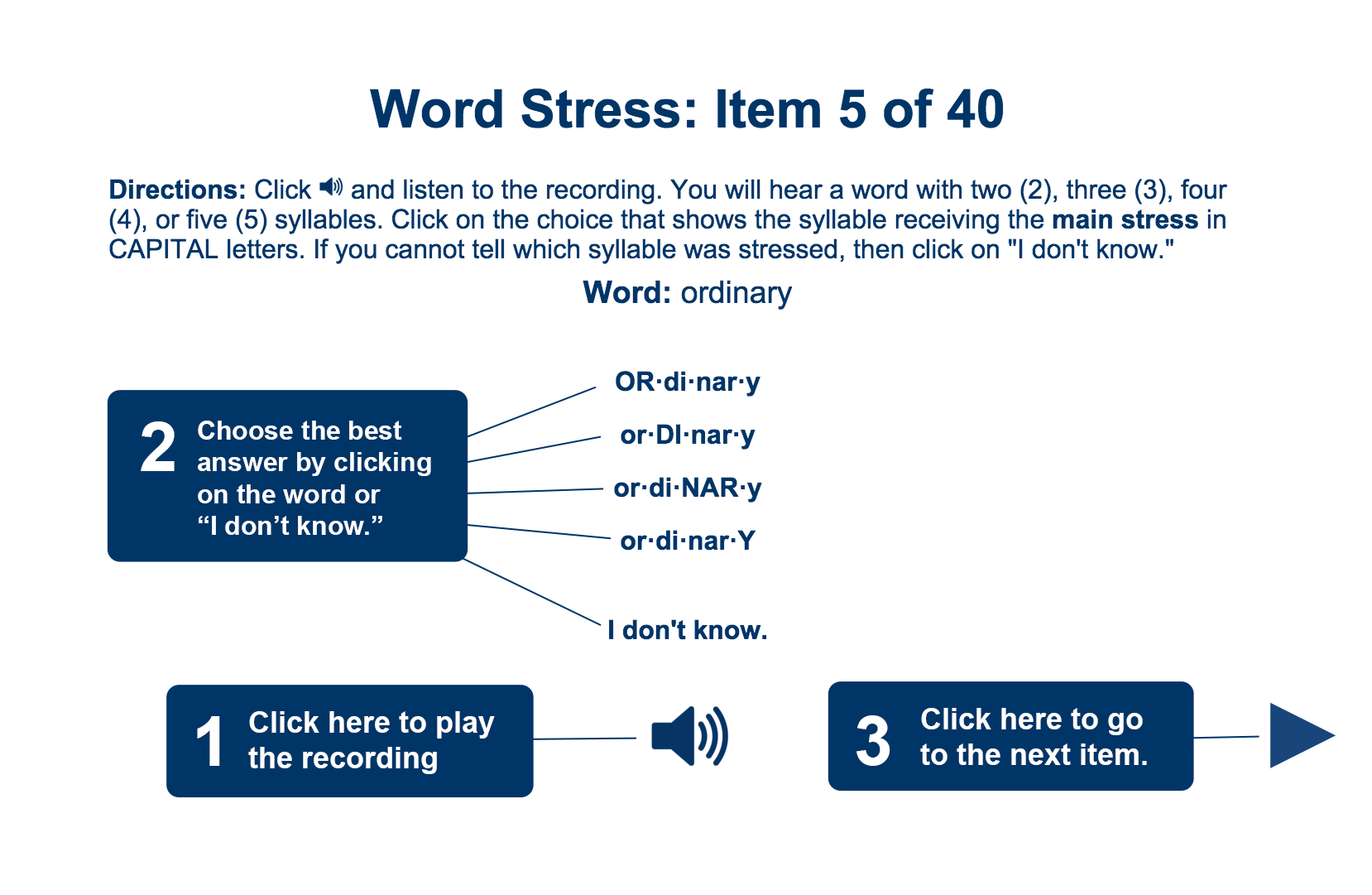
This section of the POSE test contains forty words consisting of two to five syllables each. The items in this section differ from those of the other sections in that the words in each item are presented in isolation. Different parts of speech receive stress on different syllables. If a learner happened to know that nouns, for example, were stressed on the initial syllable in two-syllable words, and was presented with a sentence in which a noun was missing, the learner would be able to correctly guess the answer of that particular item without really being able to perceive which syllable was actually stressed in the recording. The items in this section are presented as single words and not in sentences so that this type of learner knowledge will not influence the results.
Screenshot of Word Stress Section
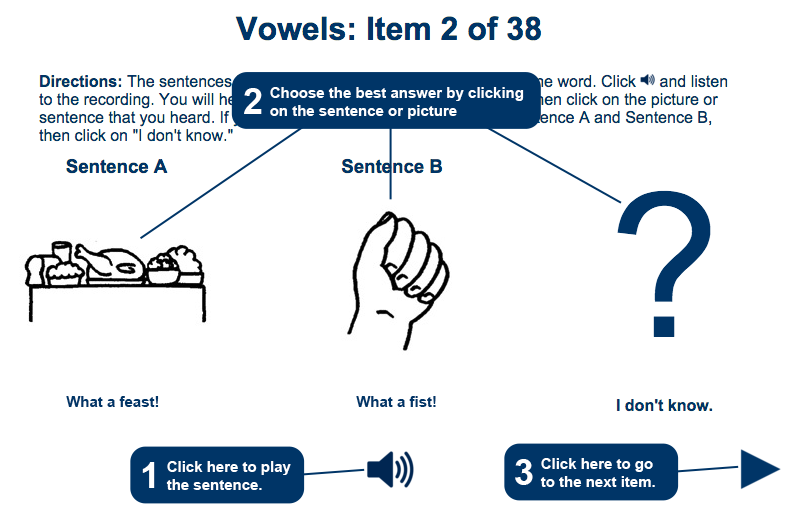
The items in the intonation section focused on the intonation at the end of an utterance. However, this section consisted of two different types of items. The first twenty items are sentences that could either be questions or statements. Learners are presented with the same sentence ending in a question mark and a period (full stop) and hear the sentence in a recording. They are then asked to indicate whether the sentence they hear in the recording is a question (rising intonation) or a statement (falling intonation). Again, if they cannot distinguish the difference, they are allowed to select "I don’t know." To help distinguish between the two choices, the question choice is presented with the word "QUESTION" in parentheses at the end of the sentence, and the statement choice is presented with the word "STATEMENT".
The last twenty items of the intonation section consist of sentences that end in tag questions (e.g. "That’s a great idea, isn’t it?"). The sentences end in either rising or falling intonation. The learners are presented with the sentence on the screen and listen to a recording of the sentence. They are then asked to determine, based on the intonation, if the speaker looking for information ("unsure" about the answer), or making a comment ("sure" about the answer). If the learner is unable to tell the difference between the two choices, he/she is allowed to select the choice labeled "I don’t know." The choices are marked "INFORMATION" and "COMMENT".
Screenshots of Intonation Section


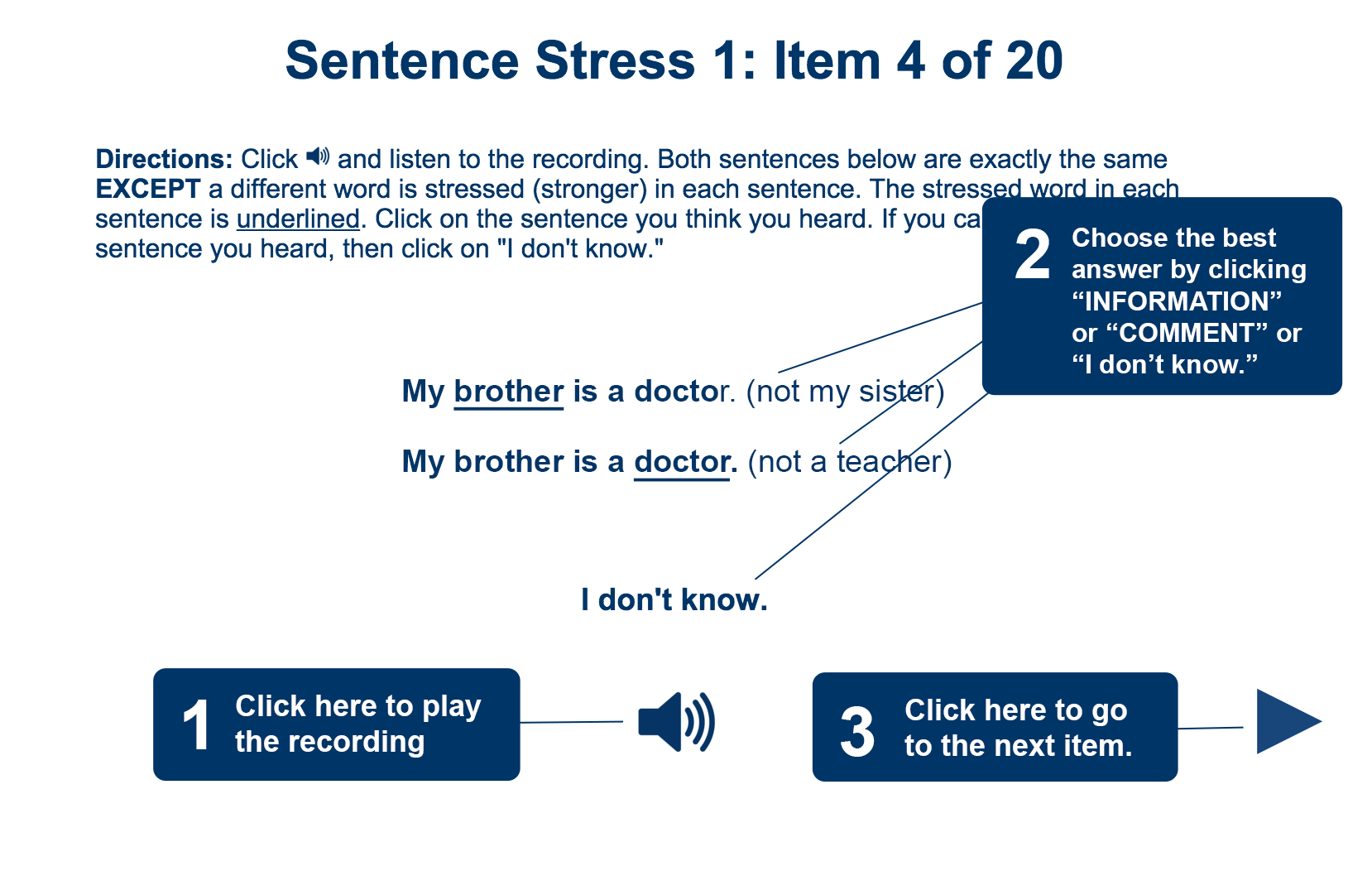
This section is divided into two parts. The first part focuses on the stressed word in a sentence. In English, stress is placed on content words, or words that carry meaning. Sometimes extra emphasis is placed on a specific word to indicate its importance in the meaning of the original utterance. For example, if a man and a woman were both standing next to each other, and you wanted to indicate the man in your utterance, you would stress the word "man" in the sentence to distinguish the man from the woman. In this first part of the sentence stress section, learners are presented with a set of minimal pair sentences with a different word underlined in each sentence. The underlined word indicates the stressed word in that sentence. Then the learners listen to a recording and are asked to select which sentence they hear according to the stressed words. If a learner cannot distinguish between the two sentences, he/she can select the option labeled "I don’t know."
The second part of this section focuses on "thought groups" (Gilbert, 1993, p.77). In this part of the POSE test, learners are presented with twenty minimal pair sentences in which the meaning of the sentence differs based on where the speaker pauses during the utterance. As with the first part of this section, learners are presented with both sentences and then listen to a recording. They are then asked to select which sentence was said. If they cannot distinguish between the possible choices, they are allowed to select the option labeled "I don’t know."
For each item in the sentence stress section, parenthetical phrases, called "rejoinders" (Henrichsen, Green, Nishitani & Bagley, 1999, p. 14), are displayed on the screen. These parenthetical phrases help clarify meaning and indicate the difference between the two sentences. The rejoinders are not included in the recording. The rejoinders are included solely to help learners distinguish between the two sentences visually.
Screenshots of Sentence Stress Section

|